

How To Get Practice With Big Data Reddit
Scrape Reddit data using Python and Google BigQuery
A user friendly approach to access Reddit API and Google Bigquery
Reddit is one of the oldest social media platforms which is yet going stiff in terms of its users and content generated every year.Behind that historic period old user interface, is the treasure trove of information that millions of users are creating on a daily footing in the course of questions and comments.
In this mail service, we will see how to get data from Reddit website using python and Google Bigquery in a footstep by step way.To illustrate this procedure, I decided to extract the information most cord-cutters, people who cut their cable connectedness and purchase streaming site subscriptions, as this phenomenon is of an involvement to me.
Equally a offset stride, permit u.s. understand the structure of Reddit website.
How is the information organized in Reddit?
The site is divided into various subreddits, with each user choosing which subreddits they would similar to subscribe to according to their involvement. These include music subreddits where links regarding music may be shared, sports subreddits where people talk in item about sports or in our instance cord-cutter subreddit where people hash out well-nigh cable connections or almost their new streaming subscriptions.
Upvote and downvote system is the essence of Reddit as information technology shows an understanding regarding a particular topic among the customs members. The more upvotes a mail gets, the more prominently information technology will be displayed on the site. It is important to note that the comments are as important as posts as they often become extended nested discussions.
Allow's go started with information collection from Reddit
Reddit API:
While web scraping is ane among the famous(or infamous!) ways of collecting data from websites, a lot of websites offering APIs to admission the public data that they host on their website. This is to avoid unnecessary traffic that scraping bots create, often crashing their websites causing inconvenience for the users. Even Reddit as well offers such API which is easy to access.
Following are the things that y'all will need for this exercise:
- Python 3.ten : Yous can download it here
- Jupyter notebook: We will be using this every bit our interactive console
- Reddit account: You will take to create a Reddit account
At that place are a few steps that you demand to follow earlier you lot get the data for your desired topic.
- Create an App:
First step after signing upward is to create an app to get Oauth keys for accessing the data. Click here to go started.
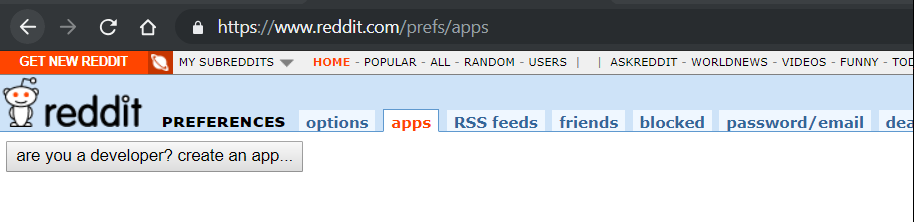
Click on the create an app as shown in the snap shot. And so a dialog box appears similar the ane below.
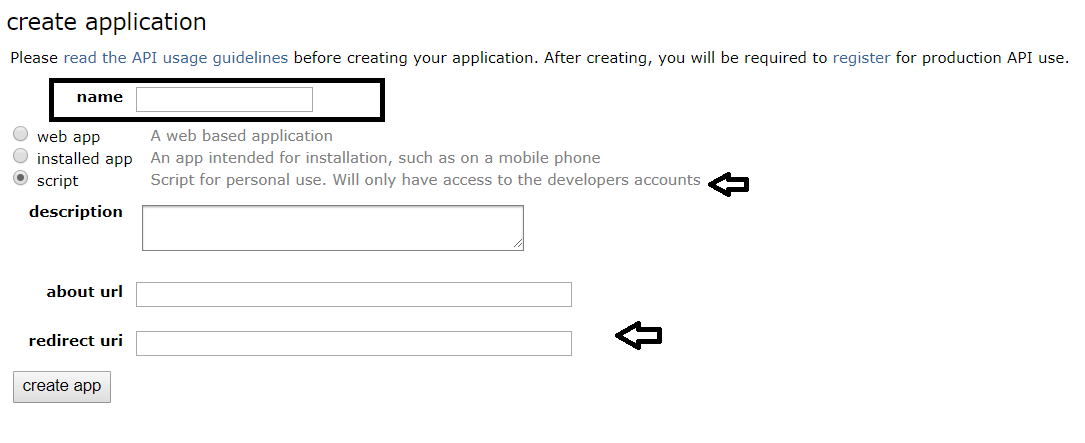
Enter a name for your app in the dialog box and click on the script as we will be using this for our personal use. Brand sure that y'all enter http://localhost:8080 in redirect URL box. Y'all can refer to praw documentation if y'all need whatever description. At present click on create app button at the bottom.
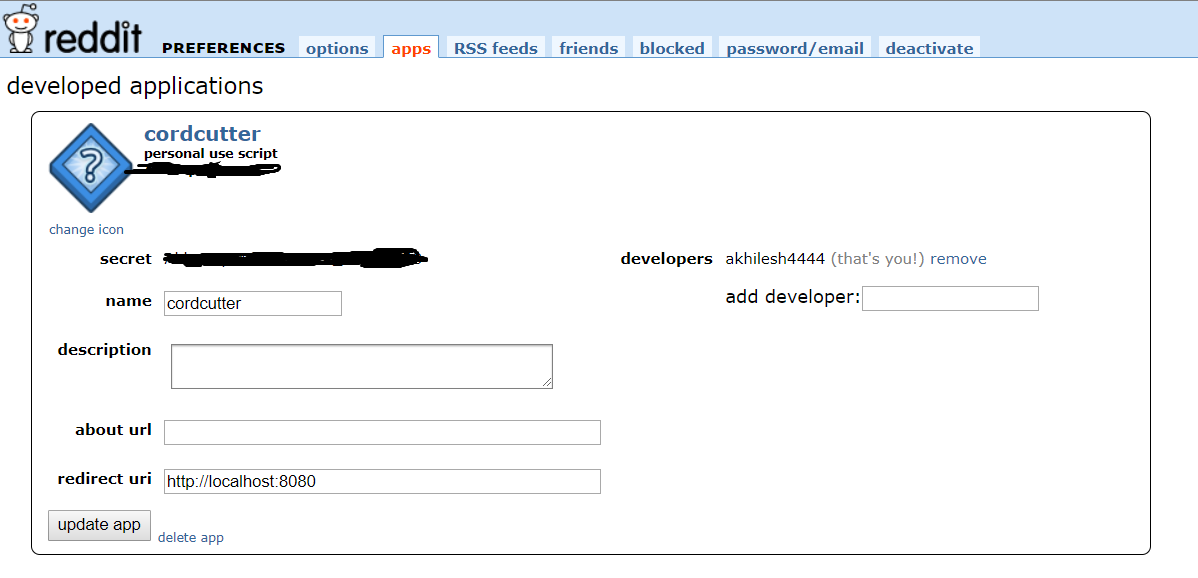
Now your application has been created. Store your 14 char personal utilize script and 27 char secret primal somewhere secure. Now you have all the credentials that are required for OAuth2 authentication to connect to Reddit API.
It'due south time to open up Jupyter notebook at present!
ii.Establish the connection
The packages that we require for this do are praw and pandas. PRAW is short for Python Reddit API Wrapper which nosotros will employ to make requests to the Reddit API. Make sure that yous accept both of them installed. Offset step is to import those packages
import praw
import pandas Next step later on importing the packages is to establish a connection with Reddit API using the credentials that we have created earlier. Client_id will exist your 14 char personal use script primal and client_secret is your 27 char secret key. Username and password are your Reddit account credentials. Rest of the code will remain the aforementioned.
reddit = praw.Reddit(user_agent='Comment Extraction (by /u/USERNAME)',client_id='**********',client_secret="***********",username='********', password='*******') Past running the above snippet of lawmaking, we will be establishing the connection and storing this information in a variable named reddit.
3.Getting the information
Every bit we have discussed earlier, we would be focusing on getting the data for 'cordcutter' subreddit.
title, score, url, id, number of comments, date of creation, trunk text are the fields that are bachelor when it comes to getting the data from Reddit API. Only as i will be not considering any fourth dimension attribute in our assay, our main focus will be to get just the bodytext(comments) from the subreddit. Refer to praw documentation for different kinds of implementations. Hither I accept limited the lawmaking to the desired output which is just body text for all comments.
To accept all the comments including the nested replies, I have to come up with a nested lawmaking with 3 parts to information technology.
Getting the list of comments ids
comm_list = []
header_list = []
i = 0
for submission in reddit.subreddit('cordcutters').hot(limit=2):
submission.comments.replace_more(limit=None)
comment_queue = submission.comments[:] In this loop, starting time nosotros are getting each submission information at the get-go of the loop then extracting all the comment ids and storing them in list.
Hither, .hot(limit) tin exist any number depending on your requirement. I take set it to 2 hither to illustrate the output, but setting it to None will fetch y'all all the acme level submissions in cordcutter subreddit. replace_more(limit=None) will help united states in considering the comments that take nested replies.
Output of this loop looks like this:
[Annotate(id='ed5ssfg'),
Comment(id='ed64a72'),
Comment(id='edth3nc'),
Comment(id='ed680cg'),
Annotate(id='ed699q2'),
Annotate(id='ed80ce8'),
Annotate(id='edau9st'),
Comment(id='edcx477'),
Annotate(id='ee0fp3g'),
Comment(id='ed5qrvh')] Getting all the nested replies
Nosotros are close to getting our desired data. In this part of the code, we will be getting the torso of each annotate id that we obtained before. If the annotate has nested replies, it will enter into the next loop and will extract data in a like style.
while comment_queue:
header_list.append(submission.title)
comment = comment_queue.pop(0)
comm_list.append(comment.body)
t = []
t.extend(comment.replies)
while t:
header_list.append(submission.championship)
reply = t.popular(0)
comm_list.suspend(respond.body) By this point, we downloaded the comments from Reddit and there would required a bit of pre-processing to download it as a csv.
Below is the collated code
comm_list = []
header_list = []
i = 0
for submission in reddit.subreddit('cordcutters').hot(limit=2):
submission.comments.replace_more(limit=None)
comment_queue = submission.comments[:] # Seed with top-level
while comment_queue:
header_list.append(submission.title)
comment = comment_queue.pop(0)
comm_list.append(comment.body)
t = []
t.extend(annotate.replies)
while t:
header_list.append(submission.title)
answer = t.popular(0)
comm_list.append(reply.body) df = pd.DataFrame(header_list)
df['comm_list'] = comm_list
df.columns = ['header','comments']
df['comments'] = df['comments'].utilize(lambda x : 10.replace('\northward',''))
df.to_csv('cordcutter_comments.csv',index = False)
You can find the terminal version of the code in my github repository.
Our terminal output looks similar this:

We take our data, merely at that place is ane challenge hither. Generally, it takes more time to go months of historical information using Reddit API. Cheers to Jason Michael Baumgartner of Pushshift.io(a.yard.a /u/Stuck_In_The_Matrix on Reddit), we accept years of historical Reddit data cleaned and stored in Bigquery which is the 2nd part of this post.
Reddit data in Bigquery:
For those who do not know what Bigquery is,
Google BigQuery is an enterprise data warehouse that solves this problem past enabling super-fast SQL queries using the processing power of Google'southward infrastructure.
Best part is querying this data would be free. Google provides kickoff 10GB of storage and first i TB of querying retention free as part of free tier and we require less than 1 TB for our job.
Lets look at how to query this information.
First click on this Google BigQuery link to get started. Google will automatically log you in with your Google credentials that are stored in your browser. If this is your first time on BigQuery, there volition be a dialog box request you to create a project.
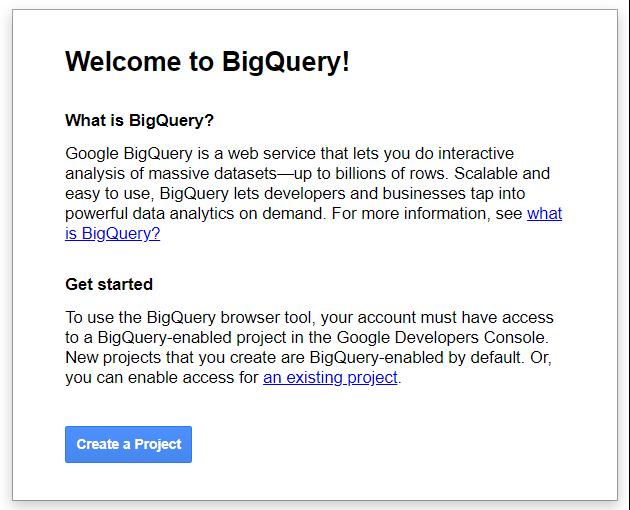
Hit on create a project button.
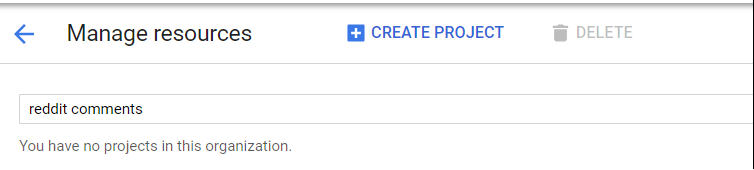
Requite a proper name to the organization and click on create project at the top.
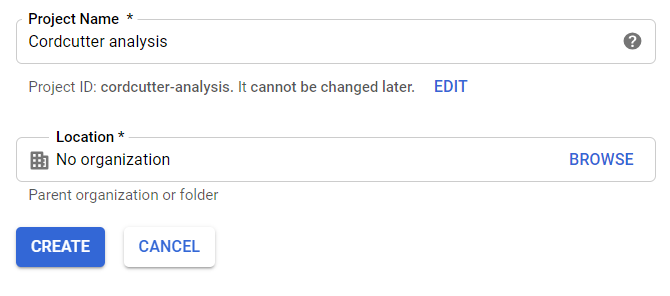
Give the proper name of the project and you tin leave the location box every bit it is for now. And so click on create. Now yous will have your project created and a dashboard appears on the screen.
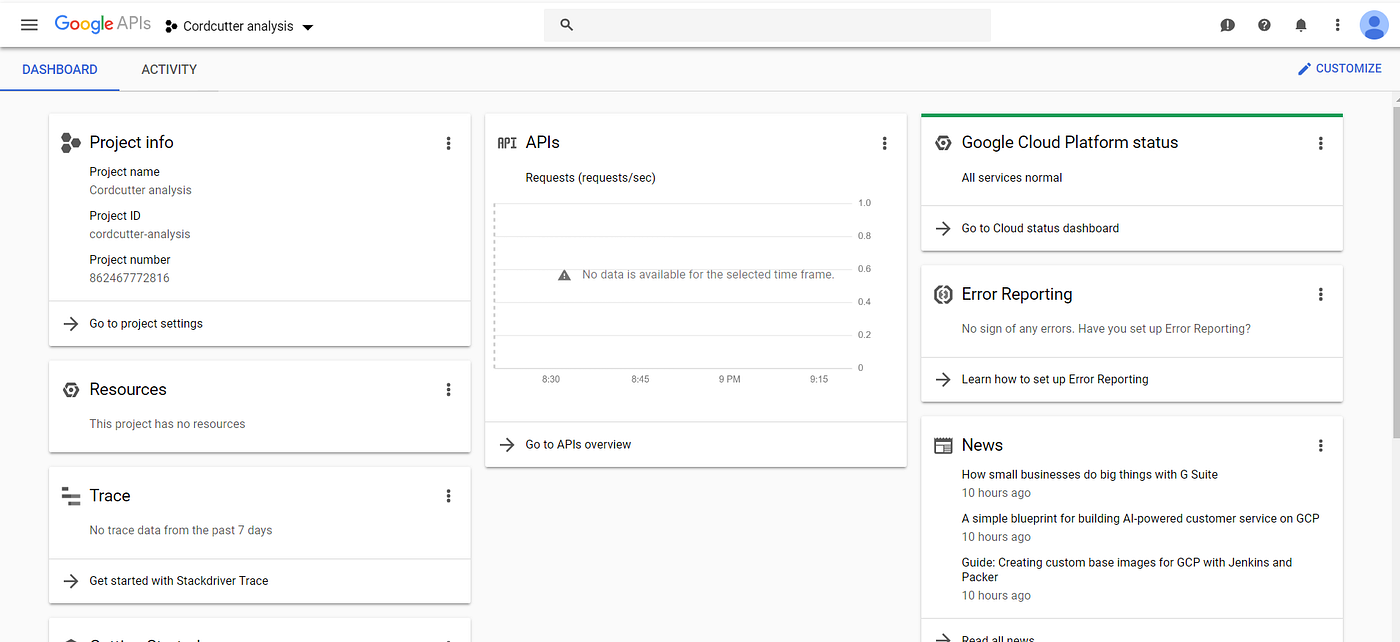
Now after this, click on the link .This will open the reddit datasets under the project that you have created. On the left hand side, you lot will come across datasets updated for each month under the schema proper noun fh-bigquery.
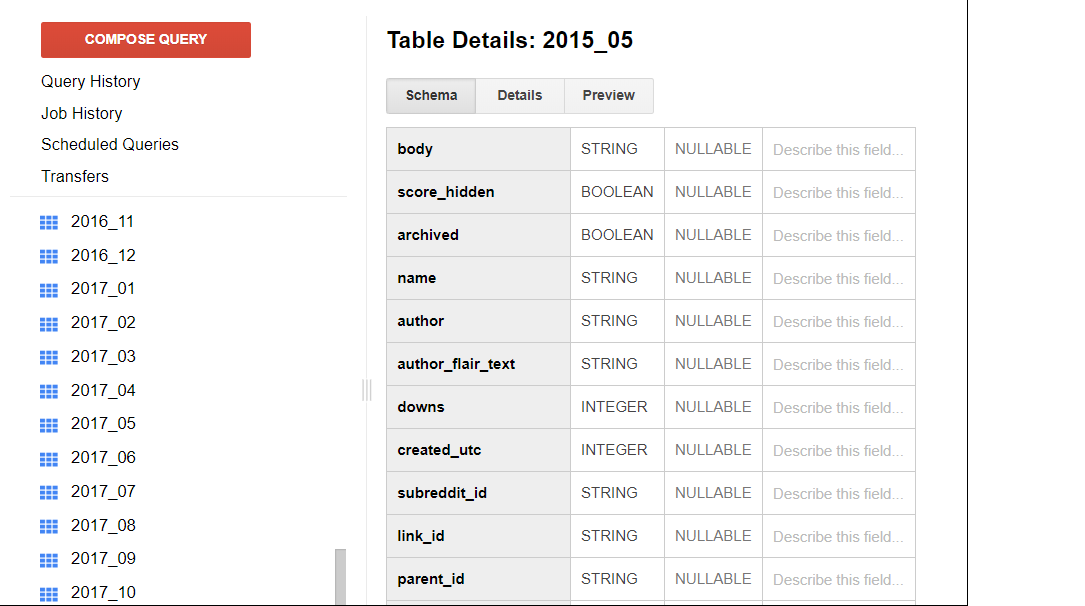
Let'south run the query to get the data for one calendar month from the table.
select subreddit,torso,created_utc
from `fh-bigquery.reddit_comments.2018_08`
where subreddit = 'cordcutters' 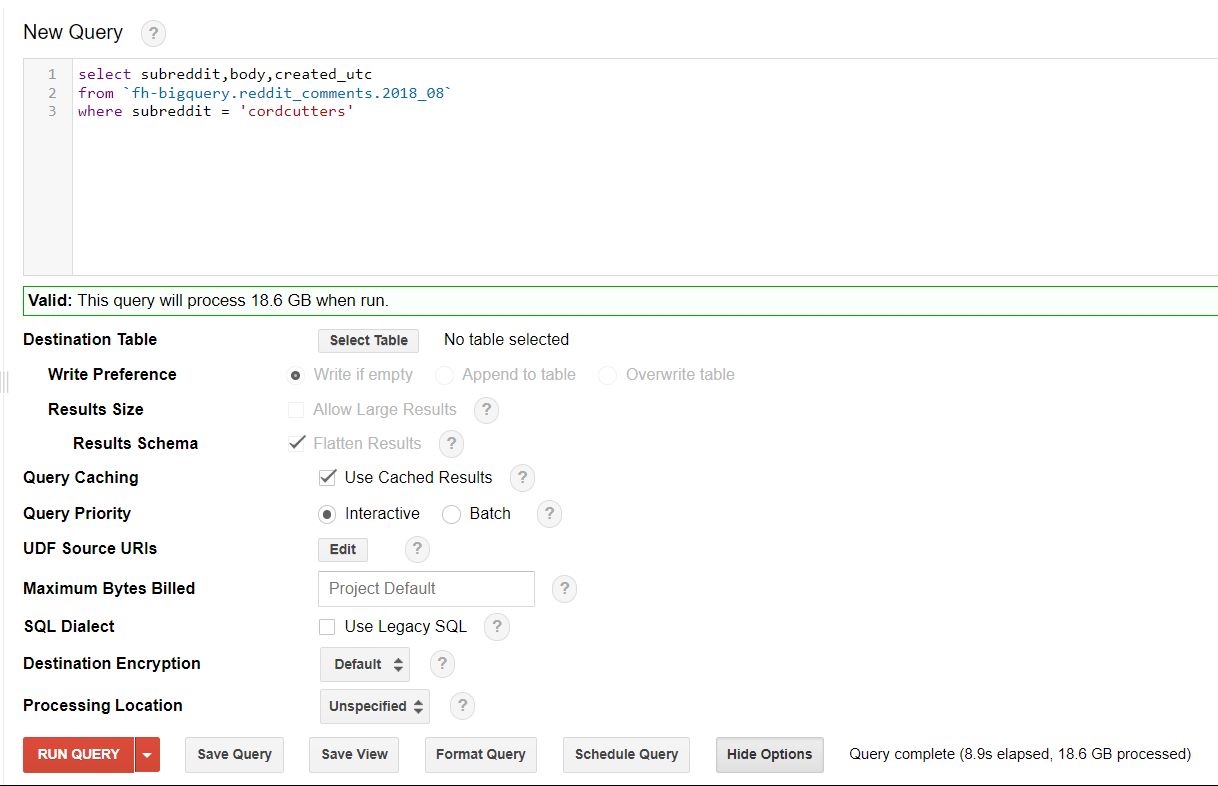
This will get y'all all the comments for 'cordcutter' subreddit. Only make sure that you exit the "Use Legacy SQL" check box in the options unchecked as the above snippet of code is in standard sql. However, you can choose your selection of sql and make changes to the lawmaking accordingly.
This is how the result looks similar and you tin can download the result as a csv by clicking "Download as CSV" button.

Here, I accept just focused on getting the data equally we requried it. If y'all want to play more than with reddit information on bigquery, you tin can refer this article past Max Woolf which goes into more detail about Reddit data in Bigquery.
Summary:
In this post, we have seen how to create OAuth2 credentials for connecting to Reddit, making information requests to Reddit API to get most contempo data and query historical data in a very fast way through Google Bigquery.
In addition to getting data through an API and Bigquery, yous might detect it interesting to wait at web scraping using Selenium and python. Following is an article about that past a fellow classmate(Atindra Bandi) at UT Austin.
That's all folks! Stay tuned to become an update on a series of articles on recommendation systems, statistics for data science and information visualizations from me in the coming weeks.

How To Get Practice With Big Data Reddit,
Source: https://towardsdatascience.com/scrape-reddit-data-using-python-and-google-bigquery-44180b579892
Posted by: rothblead1998.blogspot.com
0 Response to "How To Get Practice With Big Data Reddit"
Post a Comment